


Enterprise Data Science, Machine Learning, and AI
Jul 18, 2023
5 Common Cybersecurity Attacks on Open-Source Software
 (16)")

Access the recording of this webinar here.
Host: We are so excited to welcome Frank Yang to today’s webinar. Frank is Anaconda’s Principal Solutions Architect. With a wealth of experience designing and implementing solutions for some of the world’s largest financial institutions, Frank helps organizations leverage open-source software to execute high-value initiatives without compromising on security and governance. So now without further ado, I’ll pass things over to Frank to kick us off.
Frank Yang: Hello everyone and welcome.
In this session, we’ll talk about securing your AI, machine learning, and data science software supply chain. Let’s start off by surveying the landscape. Python is used for everything everywhere. For over a decade we’ve seen the steady rise of Python and for the past 6 years and running, Python has been the de facto language for machine learning. Python is also used across many industries and roles. Here are some of the findings of our State of Data Science report.
We see that Python is used across really every sector. And by people in roles ranging from business analyst to data scientist, operations, and more. Python is also used for end-to-end workflows. In the past, Python was perhaps looked down upon as just a scripting language, and some of you may remember having to rewrite your code in a language like C++ or Java before you could deploy into production. But nowadays Python is accepted and perhaps even preferred as a primary language. And enterprises use it for entire workflows, from data acquisition and exploration, all the way through deployment and monitoring.
And these workflows can be found everywhere: on desktops and servers, containers, and VMs. Python is also used as an embedded language in other products. And with the introduction of PyScript, it even runs in browsers as well.
So who is Anaconda in this Python world? We are both a company and a community. Anaconda is in the vast majority of the Fortune 500. And we also have an active community of tens of millions of users.
Community is extremely important to us, because this is where innovation comes from. And even the next generation of data science experts are training with Anaconda in their curriculum. We also have billions of downloads, which makes us the world’s most popular data science platform. World-class organizations trust Anaconda as the go-to provider of open-source enterprise-grade Python.
So what does Anaconda do? In brief and at a very high level, we streamline data science, starting with the installation of data science software. Python has a rich ecosystem of packages, and software is built on top of software. This is how we get increasingly sophisticated functionality. But as shown in this diagram, this also creates a complex set of dependencies between packages.

And as you can imagine, having to figure out these dependency constraints manually would be quite time-consuming and error-prone. So what we do with conda—our package manager—is automatically figure out what dependencies to bring in and ensure that all of these packages and their versions are mutually compatible. This way you don’t have to spend time wrestling with dependencies and can focus on your core data science tasks.
[5 minutes] Now, when software is installed, we also facilitate the data science workflow. As we previously saw, there are several activities in this workflow. And each of these can present challenges. At Anaconda, we provide solutions to help you get past these hurdles. We also enable deployment at scale. This previous diagram that we just saw is actually the workflow for just one data scientist.
But data science is a team sport and integral to being competitive in today’s landscape. So Python is deployed throughout your infrastructure for all sorts of use cases and across many departments and personnel.
And this scale of deployment does pose security challenges. For example, without the right tooling in place, how will you know who is downloading what packages? And from where? Also, deploying at scale creates a large surface area for potential attack. So security is definitely a concern.
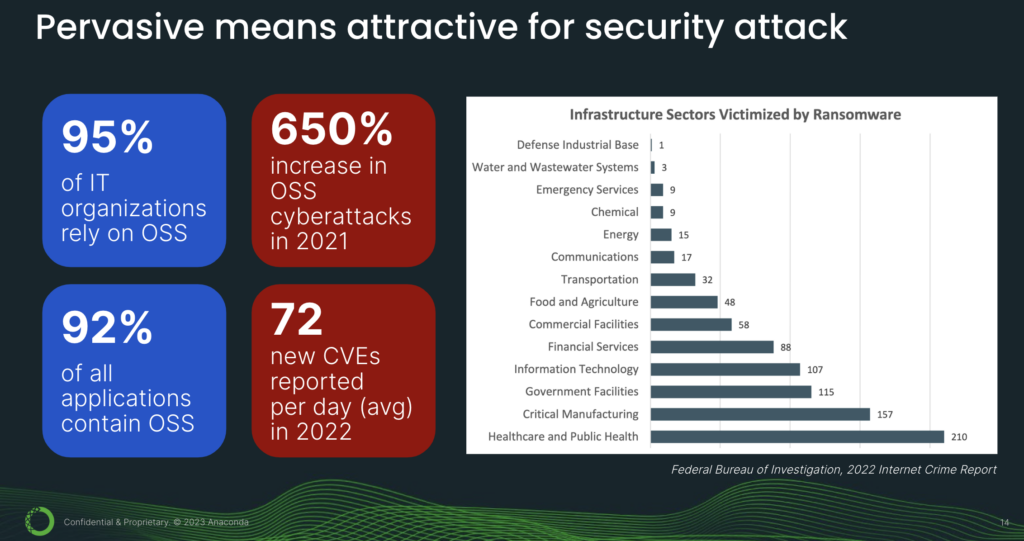
In fact, it is precisely because Python is deployed so pervasively that it is attractive for attack—because there’s a very high reward-to-effort ratio in favor of the attacker. Going from left to right (see above image), we see that open source has tremendous adoption. But at the same time, there is a concerning increase in open-source cyberattacks. In fact, in 2022, there were an average of 72 CVEs reported per day. CVEs are Common Vulnerabilities and Exposures—or security vulnerabilities. Now, if we divide 72 by 24 hours, that comes out to be 3 CVEs per hour, or a new security vulnerability every 20 minutes.
And who is affected by cyberattacks? According to the FBI’s internet crime report, the top sectors are healthcare, manufacturing, government, infotech, and financial services.
Let’s take a look at where packages come from and the challenges with community repositories. So community repositories, these are a great resource, but with caveats.
First, the good things. They have a low barrier of entry, and this is good because it encourages participation and innovation. And this is why we find a huge selection of packages on PyPI and conda-forge.
Now, if you’re running business- or mission-critical workloads, there are significant issues that you need to bear in mind. Community repositories have minimal quality control because there is no central review process. And publishing is also entirely author-driven. Stated bluntly, anybody can upload anything they want. This is actually the very nature of a community repository.
And that’s why there’s a wide range of code and metadata quality, including potential interoperability conflicts between packages. Because volunteer developers tend to focus on making their own package work and not necessarily integrating with the rest of the ecosystem. Support is also voluntary, so if you run into an incident and are in need of urgent assistance, well, that help may or may not be forthcoming.
In the case of PyPI, there is actually no build system. So someone could be sitting at home with an old desktop that’s full of malware, building packages. And there is nothing to stop them from uploading those packages. Community repositories—these free repositories—also do not implement enterprise-grade security.

And this is why we see numerous security incidents in the ecosystem. This here is really just a small sample of what you’ll find in the news. But, from these few articles, what we can glean is attacks are on the rise because they work. And even very security-savvy organizations are being breached. It’s also not just small, obscure projects. PyTorch is one of the major deep learning frameworks, and even they were compromised.
And as things evolve, attackers are becoming more creative. This last article talks about how malicious code is disguised using special Unicode characters. In fact, the volume of malicious activity has gone up so much that at one point, PyPI actually suspended the registration of new users and projects because they were just overwhelmed by this volume of attacks.
The other major community repository is conda-forge, and this is the caveat issued by their core dev team: “We do not recommend that you use conda-forge in environments with sensitive information. conda-forge’s software is built by our users, and the core dev team cannot verify or guarantee that this software is not malicious or has not been tampered with. If you use conda-forge in very sensitive environments, which we do not recommend, please remove these artifacts from your system.”
It is important to note that this caveat is coming from conda-forge themselves.
Next, let’s consider market dynamics. In 2021, the [U.S. government’s] White House issued an executive order to improve our nation’s cybersecurity. This led to the creation of the SSDF, the Secure Software Development Framework. And there are many pages of documentation about this.
But the crux of the matter is this: If we are operating in the public sector or doing business with [the] government, then we will be required to comply with security standards.
[10 minutes] And in the private sector, the market force that’s being used is liability. More specifically, liability will be placed on organizations who are using open source to build products and services—as opposed to the volunteer developers or the end consumers of those products and services. And this is because these organizations, these companies, are the ones with resources and [who] can do something about cybersecurity.
So here’s the situation. We want to leverage the innovation of open source. And we also want to comply, or rather, we have to comply with security standards. However, community repositories themselves have stated that they are not secure. Community volunteers make a very commendable effort in trying to deal with security issues, but the very nature of community repositories—being wide open to all—makes them hard to secure and easy to attack. And malicious actors exploit this.
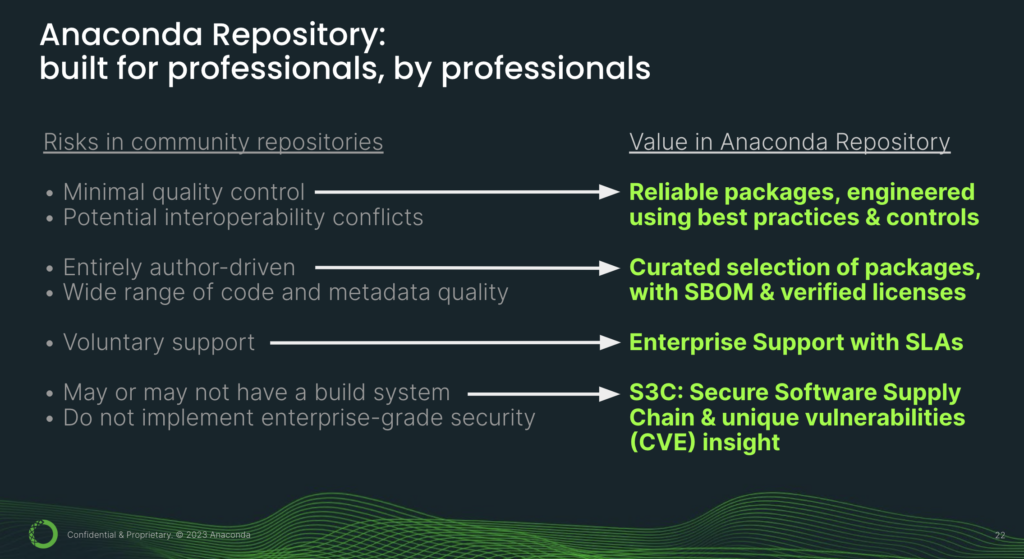
So what do we do? How can we get both innovation and security so that we can be competitive in today’s landscape? This is where Anaconda’s [Professional] Repository comes in. [This] Anaconda repository is built for professionals, by professionals. We looked at the risks in community repositories and addressed those issues.
So instead of packages with minimal quality control and interoperability conflicts, you get reliable packages engineered using best practices and built using consistent controls. What this means for you practically is that these packages are mutually compatible. So you can mix and match them to build your own unique AI models and applications.
Instead of anybody can upload anything they want, you get a curated selection of packages, complete with SBOM. SBOM is the Software Bill of Materials, which is a key component in the new security framework. You also get verified licenses, and this is especially important if you’re operating in a commercial capacity.
You get enterprise support with SLAs. What this means is you get a single point of contact for support, as opposed to trying to get ahold of volunteers with whom you have no formal engagement and most likely have never even met. S3C is our secure software supply chain and you also get our unique vulnerabilities insight.
Next, let’s take a closer look at the supply chain.
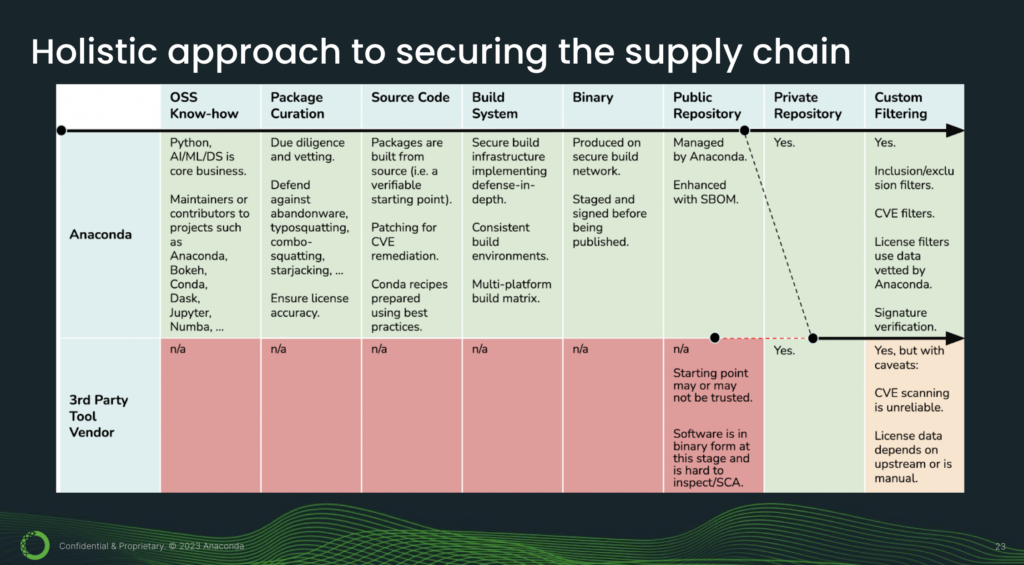
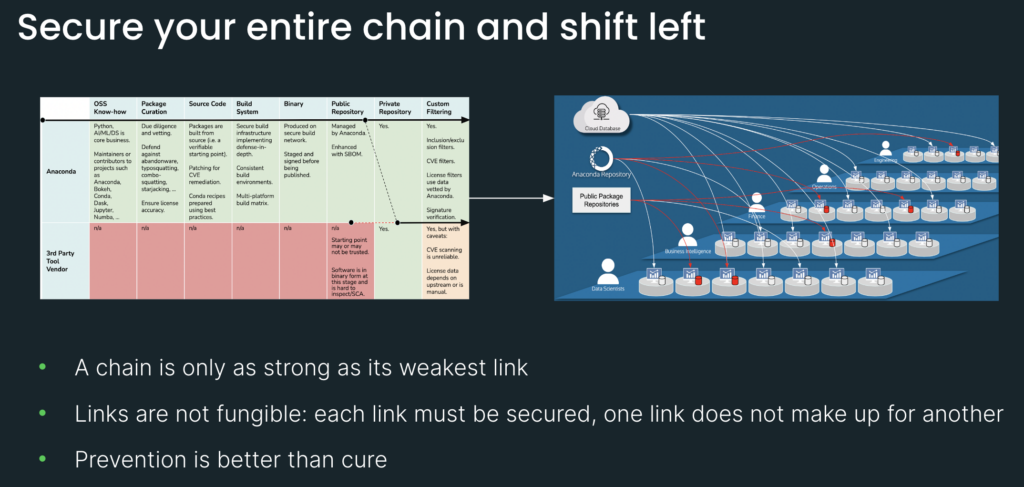
At Anaconda, we take a holistic approach to securing the supply chain. What this diagram shows is that there are multiple stages in a package’s life cycle. And the key takeaway from this slide is that each of these stages is a potential entry point for a cyberattack. So this is why it is crucial to secure each and every single link in the chain.
Now, let’s take a closer look and do a deeper dive. With the Anaconda tech stack, we start with our know-how in the open-source world. Python, AI, machine learning, and data science are our core business. And it’s been this way since day one, so it’s part of our DNA. We are maintainers and contributors to projects such as Anaconda, Bokeh, conda, Dask, Jupyter, and so forth. And this know-how makes us well-equipped to perform due diligence and vetting. This is where you can defend against issues like abandonware, typosquatting, and starjacking.
Our packages are built from source, and this is very important because source code is a verifiable starting point. We build packages using best practices, and this is done by professional engineers. Our build system implements defense in depth. What this means is we have multiple layers of defense: hardware, software, and multiple personnel. So this makes it harder for attackers to breach us.
Our binaries are staged and signed before being published. And when they are published, they are published onto a repository that is managed by Anaconda. In other words, not anybody can upload anything they want. From there, you can mirror onto your private repository and this can reside in the cloud or on-premises.
You can also apply custom filtering, for example with CVE thresholds and license filters. So that is what the pure Anaconda stack looks like.
[15 minutes] Next, let’s take a look at third-party vendor tools for comparison. So the issue with third-party vendor tools is that they really only come in at the tail end of the supply chain. This is why we see all these red “N/As,” because they just don’t do anything about these earlier links.
The typical starting point is going to be the repository. But the thing about repositories is that they’re only as good as the packages they serve. So if you’re mirroring packages from community repositories who have themselves stated that they are not secure, that does not create a secure supply chain. To further complicate matters, software at this stage of its lifecycle is in binary form and hard to do software composition analysis on; it’s hard to inspect. So we’re starting dirty and then we’re going to try to filter clean, using tools like CVE scanners.
But as we’ll see in the next few slides, third-party CVE scanners are unreliable. So this general approach of starting dirty and then trying to filter clean is not going to yield good results.
So does this mean that you shouldn’t use third-party tools? And if you’re already using third-party tools, does this mean that you need to redesign your entire architecture?
No; here is a hybrid solution you can use. You can get the benefit of all of Anaconda’s secure links here, and if you mirror from our public repository onto your private-third party repo and consume packages from there, well, then you have a secure supply chain.
So Anaconda takes great care in securing each of these links. And we also want to apply the same care to the last link in the chain, which is when software is actually installed onto your system. This is where conda signature verification comes in.
So, conda signature verification is our implementation of content trust, which is a mechanism for ensuring that software is tamper-free and exactly as it was built on our secure network—regardless of transportation medium. So what is transportation medium? In most cases, that’s going to be the internet or HTTPS.
But for customers who are extremely security sensitive and don’t trust the internet, we can ship you a drive. Concretely, what this looks like is when you do a conda install, there will be a clear message indicating that the package and metadata are signed by Anaconda and can be trusted.
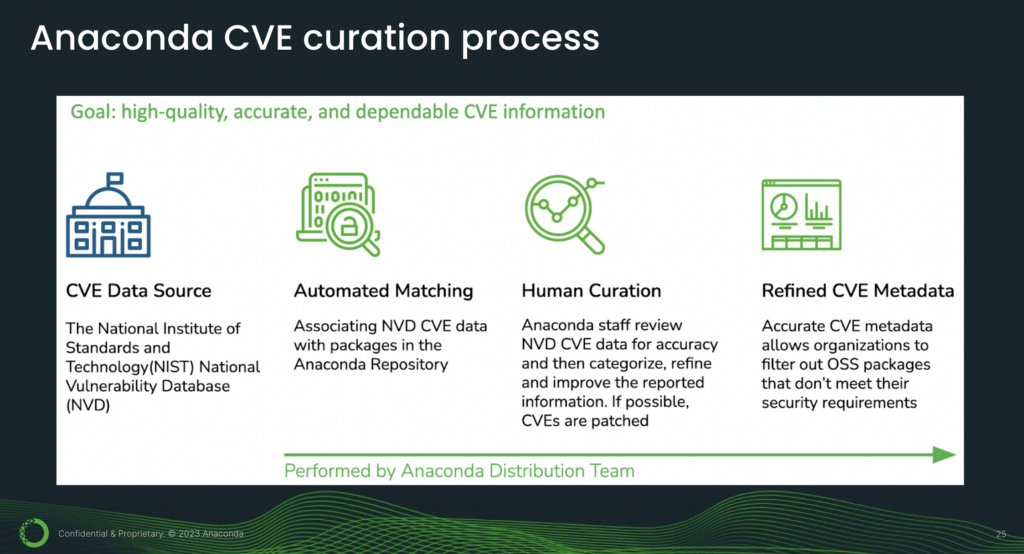
So we have secured every link in our chain. But even so, software can have bugs, and some of these bugs will be security flaws. This is what CVEs are about. CVE is short for Common Vulnerabilities and Exposures, and it’s a way of identifying and cataloging security vulnerabilities. We start with the U.S. National Institute of Standards and Technology’s National Vulnerability Database (NVD) and perform our in-house curation process.
The purpose of this process is to refine the CVE data so that we can provide you with accurate CVE reports. A key component of this process is human curation. This is where Anaconda engineers review the packages and their associated CVEs.
And you may be wondering, why human creation? Why not just automate this entire process? To answer that question, let’s look at a couple of examples.
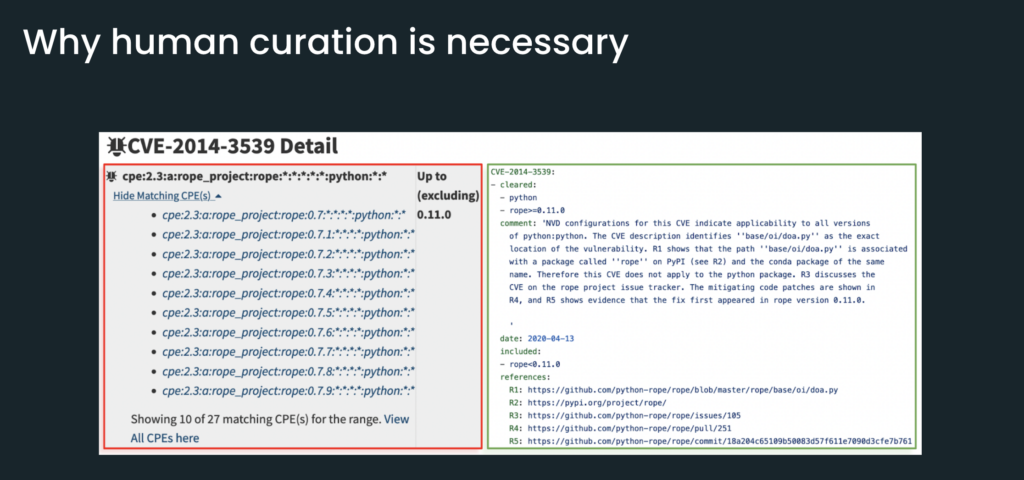
So on the left here we see data from NIST NVD, and it turns out that this data is simply wrong. In other words, there is a data quality issue.
So what Anaconda did on the right side is first, we cleared Python because it is not affected by the CVE. And we added commentary, explaining how we came to this conclusion. We also include references to support our verdict.
And this information is useful because if you need to make a security exception to bring in Python—and you will need to do that because Python is the core language itself—then having this information is going to help you properly document and justify your security override.

In this next example, NIST NVD is not wrong. But they’re not exactly correct, either. And this is because Anaconda backported a patch. In other words, the version of libxml2 that you get from Anaconda is, in fact, not exposed to the CVE. So this is an example of how we’re able to provide unique insight, because we’re actually building packages.
[20 minutes] So those two examples that we just saw are rather detailed examples, but they’re examples of how false positives can happen. False positives are false alerts. And these may seem like just a noisy nuisance, but they do, in fact, have real-world consequences. In our experience working with customer repositories, we find that reviewing false positives takes a lot of time, easily on the order of 33 weeks. This is more than half a year of productivity down the drain.
Additionally, we also have to account for psychology and user behavior. If we keep on issuing false alerts, people will get alert fatigue and ignore us. And as Aesop warned us in his fable about the boy who cried wolf, this will be a problem when something bad really does happen. The good news is, with Anaconda’s CVE curation, we eliminate these burdens for you.
The other category of issues that you’ll find with CVEs is false negatives. This is when security scans come back clean, not because there are no issues, but because of a failure to detect issues. And this is dangerous because it creates a false sense of security. Our research finds that even the most popular third-party CVE tools do not scan compiled packages correctly.
So what are compiled packages? These are libraries built using languages like C++ and Fortran. A few examples would be NumPy, pandas, PyTorch, and TensorFlow. Such packages are an essential part of AI, machine learning, and data science. So the failure to scan this category of packages correctly is a very significant security blind spot.

So why are binaries hard to scan? The reason is because in order for source code to transform into a callable library, or an executable binary, it has to go through a sequence of transformations: compiling, linking, and stripping. And this sequence of transformations is not definitively reversible.
For example, when you strip out a symbol name—and a symbol name could be a function name—that deletion is final. Once it’s gone, it’s gone. So the transformation is not definitively reversible. And that’s why it’s hard to tell exactly what binaries contain.
Intuitively, on the left, source code is human-readable. But on the right, this is what binaries look like. And as you can imagine, it is challenging to inspect this and try to figure out what sort of malware or security vulnerabilities may be embedded in there.
In fact, some third-party CVE scanners don’t even bother looking inside these binaries, so they only do a shallow scan. More advanced scanners may use heuristics. Heuristics are an educated guess, but a guess is still just a guess. And this is why we see poor performance from third-party CVE scanners.
So how does Anaconda deal with this? We actually bypass this reverse-transformation problem by starting further upstream in the supply chain, and as we saw, building packages from source. In other words, we know exactly what source code was used to produce which binary, and can therefore definitively identify the components in that binary.
We don’t have to rely on heuristics. We don’t have to guess. We then take that list of components, cross-reference it with our curated CVE database, and produce an accurate CVE report. So this is actually a unique value prop of Anaconda, because we’re starting from the very beginning of the package’s life cycle, securing each link, and tracing each link from inception all the way through installation. This is how we’re able to assure you of the provenance of a package and provide you with unique security insight.
So that was an overview of what Anaconda does. Next, let’s talk about what you can do.
[25 minutes] Here are some best practices.
1. Secure your entire chain and shift left. There are two idioms on this slide. The first of which is “a chain is only as strong as its weakest link.” And links are not fungible. This is actually a common mistake that people make, in thinking that a strong link will somehow compensate for weak links.
A concrete example of this is the repository. You can buy the most fancy, expensive repository out there, but a repository is only as good as the packages it serves. So if you’re using your fancy repo to mirror from an untrusted source, well, that doesn’t create a secure supply chain. And it’s going to leave you open to attack. So it is really not possible for a strong link to compensate for weak links. And this is why it is crucial to secure each and every link in your chain.
The other idiom is “prevention is better than cure.” What you see on the right side here is a compromised system with an extensive set of deployments. Cleaning up compromised systems is time-consuming and expensive, not to mention the impact of the breach itself, which could include data loss and reputational damage. So what we want to do is go to earlier links in the supply chain and take preventative measures—in other words, prevent this mess from happening in the first place. And this is what we mean by shifting left.
2. Counter imperfection with defense in depth. The reality is that security tools have holes. We have done a lot of research, and we continue to do research, and we have yet to find a CVE scanner without flaws. So what can you do? One strategy is to mitigate risk by assembling complementary tools.
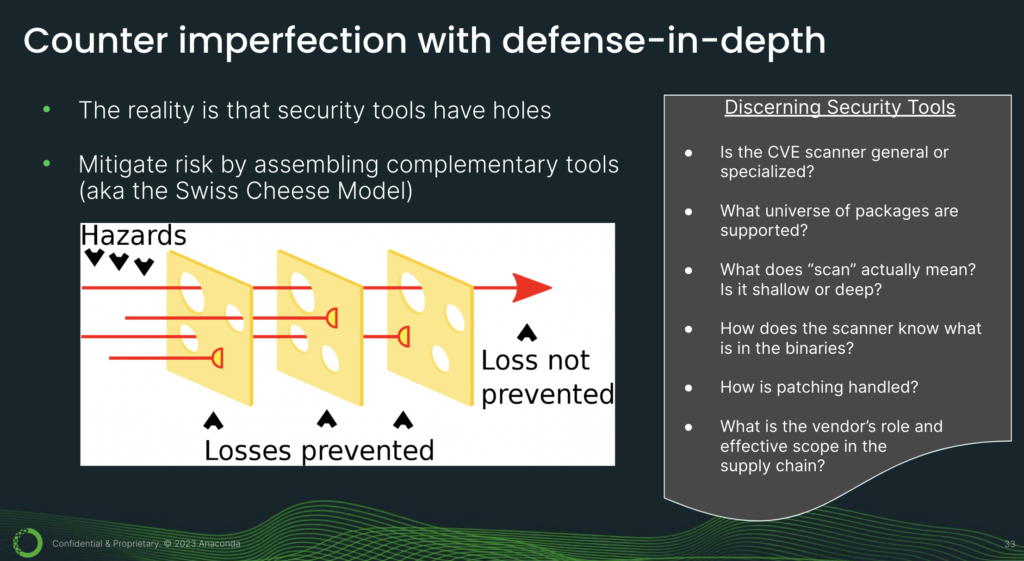
This is sometimes referred to as the Swiss cheese model. So how do you identify complementary tools? You will have to understand the nuances. For example, is the CVE scanner general, or specialized? The good thing about general CVE scanners is that they provide broad coverage for many different artifact types. But they’re also not very accurate.
With Anaconda’s CVE solution, our specialization, our focus, is Python. And this includes all of those complex compiled packages that are essential to AI, machine learning, and data science. So you have to understand the different strengths and weaknesses of tools to figure out how they may be complementary.
Something else to watch out for is, supply chain is a very hot topic and there is a lot of marketing and hype out there. So you have to be a discerning consumer. For example, if a vendor is pitching a tool that claims to secure your supply chain, you’ll have to understand: what is the vendor’s role and effective scope in the supply chain? For instance, if they only provide CVE tools, but don’t build packages, how will they know if a package has been patched?
And if they don’t know if a package has been patched, how will they provide you with an accurate CVE report? Similarly, if a vendor does not manage the CI/CD system (this is the system used to build packages), then how will they secure it? How can someone secure a process that they aren’t even part of?
So these are some of the critical questions that you will need to know the answers to as you assess the various tools out there and design your architecture for secure AI.
As AI becomes more crucial, so too does securing its supply chain. And this is not just because of the important use cases of AI, but also simply because as Python deployments grow, so too does the surface area of potential attack. So it becomes more crucial to secure your supply chain of Python components.
World-class organizations trust Anaconda as the best-of-breed solution. So leverage Anaconda, because what we provide are the trusted building blocks of AI—so that you can focus on your strategic differentiators.
So that’s it. We hope this session was useful for you. And if you would like to learn more, please connect with us. Thank you for tuning in.
Get in touch to learn more about Anaconda.

